In a significant advancement for AI efficiency, Alibaba’s Qwen team has open-sourced QwQ-32B, a large language model that achieves comparable performance to much larger models while dramatically reducing computational costs.
Released on March 6, the QwQ-32B model has just 32 billion parameters yet matches or even exceeds the performance of DeepSeek-R1, which has 671 billion parameters (with 37 billion activated). This breakthrough demonstrates that smaller, more efficient models can achieve high-level reasoning capabilities previously thought to require massive parameter counts.
According to Alibaba’s Qwen team, QwQ-32B showcases “the effectiveness of applying reinforcement learning to a strong foundation model that has undergone large-scale pre-training,” potentially establishing a viable path toward artificial general intelligence.
Impressive Benchmark Performance
QwQ-32B demonstrates exceptional performance across multiple key benchmarks:
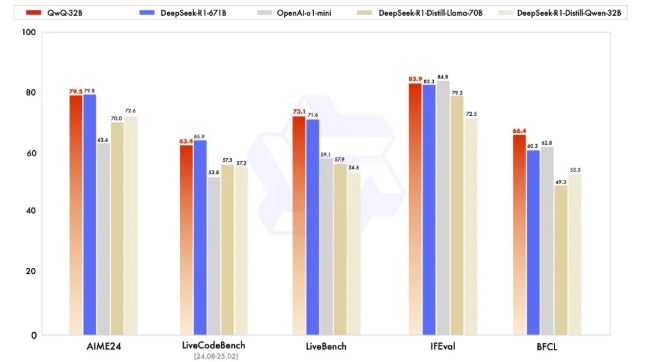
- On AIME24, which tests mathematical reasoning, QwQ-32B performs on par with DeepSeek-R1, significantly outperforming o1-mini and R1 distillation models of similar size
- In LiveCodeBench, which evaluates coding abilities, it matches DeepSeek-R1’s performance
- On LiveBench, described as “the most challenging LLM evaluation leaderboard” led by Meta’s Chief Scientist Yann LeCun, QwQ-32B scored higher than DeepSeek-R1
- For instruction following capability in Google’s IFEval, it outperformed DeepSeek-R1
- In UC Berkeley’s BFCL test, which assesses accurate function or tool calling, it also surpassed DeepSeek-R1
Cost-Effectiveness Breakthrough
“X user @N8Programs shared comparisons showing QwQ-32B’s impressive efficiency:”
- QwQ-32B achieves a LiveBench score of approximately 72.5 at a cost of about $0.25
- DeepSeek-R1 scores around 70 points at a cost of about $2.50
- o3-mini scores around 75 points at a cost of approximately $5.00
This positions QwQ-32B between R1 and o3-mini in performance while costing just one-tenth of either model, representing a significant breakthrough in the performance-to-cost ratio.
The Secret Weapon: Reinforcement Learning
QwQ-32B’s exceptional performance stems from its multi-stage reinforcement learning strategy:
- Initial phase: Focused on reinforcement learning for mathematical and programming tasks, using direct validation methods rather than traditional reward models. Mathematical problems received feedback by validating the correctness of generated answers, while programming code was evaluated through execution servers testing against test cases.
- Extension phase: Added RL training for general capabilities using universal reward models and rule-based validators, enhancing broader abilities while maintaining strength in math and programming.
Research shows that as RL training rounds increased, the model’s performance in both mathematics and programming domains continuously improved, validating this approach’s effectiveness.
An Open-Source Movement Toward “Smart Efficiency”
QwQ-32B is now available on Hugging Face and ModelScope under the Apache 2.0 license, with direct access also provided through Qwen Chat.
The Qwen team stated that QwQ-32B represents just their first step in enhancing reasoning abilities through large-scale reinforcement learning. Future plans include combining stronger foundation models with RL powered by scaled computing resources and exploring the integration of agents with RL to achieve extended reasoning.
This development aligns with Alibaba’s recently announced AI strategy, which includes plans to invest over 380 billion yuan in cloud and AI infrastructure over the next three years—exceeding their total investment from the past decade.
As the industry faces diminishing returns from simply increasing model size, QwQ-32B’s achievements may lead a new direction in AI technology development, pushing the paradigm from “brute force miracles” toward “elegant intelligence.”